Lo scopo del presente articolo è mostrare l’evoluzione della ISO 27005, presentare un paradigma metodologico compatibile e alternativo per la gestione del rischio cibernetico e osservare alcune delle minacce riguardanti l’intelligenza artificiale.
ISO 27005:2018 e considerazioni generali
La ISO 27005 del 2018 (la terza edizione), presenta una tabella molto interessante contenuta nell’Annesso-C che include l’origine delle minacce più comuni, le motivazioni alla base degli attacchi e le possibili conseguenze. La tabella, seppur importante, risente del passare del tempo e merita alcune riflessioni; la ISO del 2018 prevede 5 tipologie di soggetti:
- Hacker
- Criminali informatici
- Terroristi
- Spionaggio industriale
- Interni (intesi come membri interni di un’organizzazione)
Ad un primo esame i soggetti proposti sono ben distinti, a ciascuno di questi sono state attribuite delle motivazioni di attacco; ad esempio, ai criminali informatici sono state attribuite le seguenti:
- Criminali informatici
- Distruzione di informazioni
- Distribuzione illegale di materiale riservato
- Guadagno economico
- Alterazione non autorizzata dei dati
Queste motivazioni, a loro volta, possono dare origine a diverse conseguenze che la ISO propone in ulteriori tabelle ed elenchi. A parer di chi scrive, il problema essenziale della ISO 27005:2018 è che non è più in grado di essere aderente allo scenario di rischio attuale. Facciamo un esempio: si prenda in considerazione la motivazione legata al “ricatto”, la ISO associa tale motivazione ai seguenti soggetti
- Ricatto
- Terrorismo
È noto, però, che i recenti attacchi cyber si basano su una logica di ricatto, ogni qualvolta la vittima si rifiuta di pagare il riscatto chiesto dagli hacker. Ormai questa è una prassi nota e consolidata: si tenga in considerazione la minaccia operata attraverso i ransomware, la strategia di doppia estorsione si basa sul ricatto. L’Enciclopedia Treccani definisce il ricatto:
Estorsione di denaro, o di altri profitti illeciti, con minacce che costituiscono coazione morale
Di conseguenza sarebbe più opportuno associare la motivazione ricatto sia alla minaccia terrorismo che alla minaccia hacker e anche, di conseguenza, alla minaccia criminali informatici.
ISO 27005:2022 e considerazioni generali
La ISO 27005:2022 cambia radicalmente il paradigma di gestione del rischio: lo standard propone un approccio basato sulla “sorgente di rischio” e una maggior attenzione agli scenari operativi dell’organizzazione. Un esempio è rappresentato dallo schema seguente denominato “Risk assessment based on risk scenarios“.

L’approccio evoluto tiene in considerazione il fatto che gli scenari operativi possano avere importanza variabile in condizioni di tempo variabile: un progetto di dieci anni manterrà il suo valore strategico per un periodo di tempo non necessariamente pari a tutta la lunghezza progettuale. Questo richiede che siano tenuti in considerazione tutti i fattori che possono essere impattati dalla minaccia. In tal senso è utile osservare che la ISO 27005:2002 presenta uno schema apposito per la gestione dei rischi basati sugli eventi.
| Risk source | Description |
|---|---|
| State-related | States, intelligence agencies |
| Organized crime | Cybercriminal organizations (mafia, gangs, criminal outfits) |
| Terrorist | Cyber-terrorists, cyber-militias |
| Ideological activist | Cyber-hacktivists, interest groups, sects |
| Specialized outfits | “Cyber-mercenary” profile with IT capacities that are generally high from a technical stand-point. |
| Amateur | Profile of the script-kiddies hacker or who has good IT knowledge; motivated by the quest for social recognition, fun, challenge. |
| Avenger | The motivations of this attacker profile are guided by a spirit of acute vengeance or a feeling of injustice. |
| Pathological attacker | The motivations of this attacker profile are of a pathological or opportunistic nature and are sometimes guided by the motive for a gain. |
È sorprendente notare quanto si sia evoluto, esteso e maggiormente dettagliato l’elenco delle sorgenti di rischio. In particolare è bene chiarire che vi può essere una forte interazione tra alcune di queste categorie: un esempio potrebbe essere quello che intercorre tra state-related e specialized outfit e che, in questo periodo, si ritrova alla base di alcuni cyber attacchi russi contro target europei. Gli attacchi informatici perpetrati da uno stato (state related), di fatto, fanno spesso uso di mercenari (specialized outfit) assoldati per condurre l’offensiva. È altrettanto interessante analizzare gli obiettivi mirati riportati nella tabella A.9 dello standard e che qui vengono sintetizzati:
- Spionaggio
- Operazioni di intelligence di tipo statale o economico.
- Gli attaccanti mirano spesso a un’infiltrazione a lungo termine nei sistemi informativi mantenendo la massima discrezione.
- Settori presi di mira: armamenti, spazio, aeronautica, farmaceutico, energia e attività statali (economia, finanza, affari esteri).
- Pre-posizionamento strategico
- Infiltrazione nei sistemi senza un obiettivo immediato, ma con l’intenzione di poter attaccare in futuro.
- Esempi: compromissione di reti di telecomunicazioni o siti di informazione per lanciare operazioni di influenza politica o economica.
- Attacchi su larga scala per formare botnet rientrano in questa categoria.
- Influenza
- Diffusione di informazioni false o manipolate.
- Mobilitazione di leader di opinione sui social network.
- Attacchi per distruggere reputazioni, rivelare dati riservati o danneggiare l’immagine di un’organizzazione o di uno Stato.
- Scopo: destabilizzazione o alterazione della percezione pubblica.
- Ostacolo al funzionamento
- Operazioni di sabotaggio volte a rendere un servizio digitale o fisico non disponibile.
- Esempi: attacchi DDoS (Distributed Denial-of-Service), interruzione di servizi critici industriali, danni fisici a infrastrutture IT.
- Gli attacchi possono mirare a saturare i sistemi informativi o a causare guasti hardware complessi da risolvere.
- Scopo lucrativo
- Attacchi finalizzati a guadagni finanziari diretti o indiretti.
- Legati spesso al crimine organizzato.
- Esempi: frodi online, riciclaggio di denaro, estorsione, manipolazione dei mercati finanziari, falsificazione di documenti amministrativi, furto d’identità.
- Alcuni attacchi con scopo di lucro utilizzano tecniche di spionaggio o ransomware per paralizzare un’attività e chiedere riscatti.
Modello RoA: proposta di modello
Molto spesso le aziende si domandano come approcciare i modelli metodologici proposti dagli standard. Quando si pensa ad un asset spesso si considerano quelli fisici e non quelli logici oppure si trascurano aspetti di valutazione rilevante. Nel dubbio su “cosa” includere nello scenario di attacco è bene ricordare che vi è un metodo semplice ma efficace per non sbagliare. Bisogna porsi la domanda sulla ragione di attacco (reason of attack). Che motivo avrebbe un attaccante per condurre un offensiva? Nel tentativo di rispondere alla domanda si evidenzieranno sia gli asset coinvolti, sia le conseguenze degli attacchi, sia le minacce che potrebbero impattare sull’organizzazione.
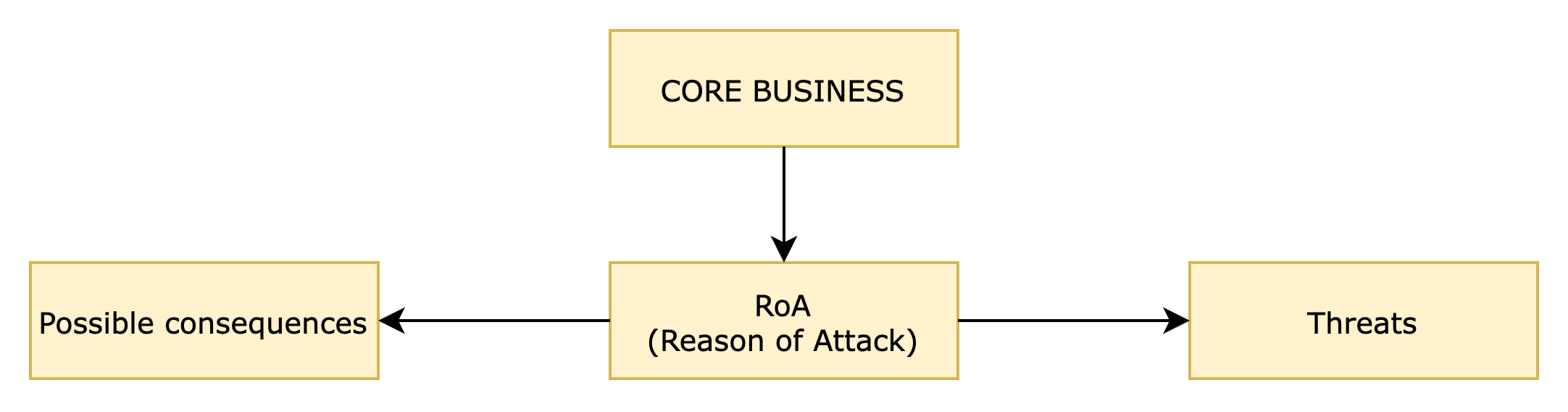
Come si nota dal grafico, l’analisi deve iniziare dal core business che deve essere individuato con chiarezza. Essendo il fulcro dell’attività organizzativa, esso è rappresentato da una serie eterogenea di potenziali asset oggetto di attacco; potrebbero essere infrastrutture, documenti, risorse umane. Ciascuna potrebbe essere alla base di una Reason of Attack (RoA).
Poichè la RoA può variare a seconda degli asset identificati, questo apre lo scenario ad attacchi ibridi basati su una moltitudine di tecniche e “fasi”: ogni asset può quindi essere attaccato con metodi, tempi e tecniche differenti e per tale ragione deve essere protetto in modo quanto più possibile personalizzato.
La RoA, se opportunamente analizzata, può fornire informazioni preliminari sulle minacce e sulle possibili conseguenze; i dati ottenuti possono essere utilizzati per ottimizzare le strategie di difesa e protezione delle informazioni.
In merito alle minacce è bene chiarire che, seppur molto rilevanti da individuare, questo approccio metodologico permette una maggiore tolleranza di errore nella loro individuazione. Si suppone che le minacce possano cambiare tipologia e “forma” con il passare del tempo e con il formarsi di scenari appositi. Pertanto, benché rilevanti, il modello tiene conto della loro alta variabilità e concentra l’attenzione principale sul RoA e sulle possibili conseguenze.
Gestione della complessità organizzativa
Il modello tiene in considerazione il core business aziendale e quindi un set ridotto di informazioni, processi e politiche rispetto la totalità degli asset dell’organizzazione. Questa scelta è voluta al fine di mantenere il modello applicabile, efficiente, agile e gestibile.

In tal senso si parte dal presupposto che il core business sia composto da una serie di strategie essenziali per la vita dell’organizzazione; nel caso del diagramma, ad esempio, sono sette. Ogni strategia costituisce un elemento fondamentale senza il quale l’organizzazione potrebbe andare in crisi; potrebbero essere linee di produzione di prototipi o di servizi essenziali per l’organizzazione. Ogni strategia è strutturata in asset critici, obiettivi e contatti.
- Gli asset critici sono quelli essenziali per procedere allo sviluppo della strategia e includono dispositivi, apparati, informazioni, documenti, dati, senza i quali è impossibile procedere alla strategia. Non sono inclusi tra i critical assets tutti quei componenti che possono essere rimpiazzati, acquistati nuovamente, sostituiti senza problemi.
- Gli obiettivi sono il traguardo a cui deve giungere la strategia. Generalmente potrebbero essere rappresentati da un prodotto finale, da un servizio consolidato, da un livello produttivo, da un target della linea di fornitura. Gli obiettivi vanno difesi dagli attacchi in modo che possano essere sempre raggiungibili ed in modo che non venga interrotta la linea di produzione.
- I contatti sono invece i punti di riferimento interni ed esterni utili per il mantenimento dell’operatività ed il successo della strategia. Questo implica, ad esempio, che un particolare fornitore interessato dalla strategia venga considerato un contatto e come tale deve essere monitorato e gestito. Standards come la ISO 27001, i Critical Security Controls e normative come la NIS 2, prevedono la gestione dei fornitori sia prima dell’ingaggio, che in corso di fornitura e anche in chiusura dei rapporti.
Per maggiori informazioni si faccia riferimento ai seguenti articoli:
Controllo e gestione dei Service Providers
NIS 2 – Informazioni, sicurezza e fornitori
Integrazione normativa
La RoA consente di interfacciarsi con normative attualmente in vigore come la Direttiva Europea 2555/2022 (NIS2), il Regolamento Europeo 2554/2022 (DORA), la ISO 27001, la ISO27005, i Critical Security Controls, Regolamento Europeo per il trattamento dei dati personali (GDPR).

Nel modello proposto la RoA permette all’organizzazione di concentrarsi sugli aspetti principali della strategia, andando ad acquisire dai singoli standard gli obiettivi più rilevanti. La RoA, inoltre, risponde ai principi delle normative vigenti come, ad esempio, il GDPR. Si pensi alla valutazione d’impatto (di cui all’art.35 della normativa) o al principio di accountability: in questi casi è necessario porsi la domanda in merito a cosa proteggere ma soprattutto da cosa e come, andando a giustificare così una ragione di attacco.
Evoluzione da intelligenza artificiale

La RoA tiene conto dell’aumento di complessità dello scenario, come anticipato nel 1998 dal professor Donn B. Parker. Con un volume di dati più ampio, l’attaccante dovrà “selezionare” quelli di suo interesse, cercando di ottenere tale selezione da un sistema d’intelligenza artificiale (integrato o di terze parti). Un esempio può essere un motore di ricerca dotato di algoritmo intelligente che consente di fare interrogazioni su base tematica rispetto al contenuto. Questo consentirebbe all’attaccante di selezionare e dare una priorità ai file da trasferire e/o distruggere.

Dal punto di vista difensivo diviene complesso proteggere una grande mole di dati e di conseguenza sarà necessario individuare quegli elementi che sono prioritari per il core business e garantire loro il massimo della sicurezza. Questo non significa che gli altri elementi saranno al di fuori del perimetro di sicurezza ma che quelli appartenenti al core business saranno suscettibili di una maggiore vigilanza. Il paradigma applicato è il medesimo della NIS 2 quando si parla di soggetti essenziali e soggetti importanti: non vi è differenza tra le misure di sicurezza ma tra frequenza e intensità dell’attività di vigilanza.
Intelligenza artificiale e rischi cibernetici
Il 14 febbraio 2025 l’Agenzia per l’Italia Digitale (AgID) ha pubblicato un documento denominato “Bozza di linee guida per l’adozione di IA nella pubblica amministrazione” (link al documento). All’interno sono descritte molte procedure d’implementazione dell’intelligenza artificiale nella pubblica amministrazione e anche molte tecniche di protezione dai rischi derivanti da tale implementazione. A questo proposito AgID chiarisce che:
la PA PUÒ fare riferimento alle norme tecniche UNI ISO 31000 e alla ISO/IEC 23894
La UNI ISO 31000 si occupa di gestione del rischio, mentre la ISO/IEC 23894 si occupa dei rischi espliciti della I.A. e ha il seguente titolo “Information technology — Artificial intelligence — Guidance on risk management“.
Tecniche di attacco
AgID seleziona quattro tipologie di attacco principali:
- Evasion Attacks: questa categoria di attacchi ha come obiettivo quello di generare un errore nella classificazione del modello introducendo perturbazioni (spesso impercettibili per l’uomo) negli input del modello, denominate adversarial examples. Lo scopo è quello di indurre il modello a prevedere un valore desiderato dall’attaccante o determinare una riduzione dell’accuratezza del modello.
- Poisoning Attacks: categoria di attacchi ha come obiettivo degradare le prestazioni di un modello o fargli generare uno specifico risultato alterando (avvelenando) i dati di addestramento del modello. Si suddivide in quattro sottocategorie:
- Availability Poisoning: determinano una violazione della disponibilità del modello tramite una degradazione delle sue prestazioni su tutti i sample di dati.
- Targeted Poisoning: determinano una violazione dell’integrità del modello alterandone la previsione su un numero ridotto di sample mirati.
- Backdoor Poisoning: analogamente agli attacchi targeted poisoning determinano una violazione dell’integrità del modello, in questo caso tuttavia l’obiettivo è indurre in errore il modello in risposta a uno specifico sample di dati (denominato trigger).
- Model Poisoning: modificano direttamente il modello addestrato iniettandogli funzionalità malevole.
- Privacy Attacks: ha come obiettivo compromettere le informazioni degli utenti ricostruendole a partire dai dati di addestramento.
- data reconstruction: ricostruiscono le informazioni a partire dalle informazioni aggregate;
- membership inference: determinano se un particolare record è stato incluso nel dataset utilizzato per l’addestramento di un modello, compromettendo le informazioni dell’utente.
- model extraction: ottengono informazioni estraendo informazioni sul particolare modello utilizzato, come la sua architettura o i suoi parametri.
- property inference: accedono a informazioni globali sulla distribuzione dei dati di addestramento interagendo con il modello.
- Abuse Attacks: hanno come obiettivo alterare il comportamento di un sistema di IA generativa per adattarlo ai propri scopi come, ad esempio, perpetrare frodi, distribuire malware e manipolare informazioni.
È bene tenere in considerazione il fatto che queste modalità di attacco, soprattutto ad un certo livello di complessità, possono essere “miscelate” per dare origine ad un’azione offensiva complessa e di difficile mitigazione, analizziamo alcuni esempi tra quelli suggeriti da AgID.
Esempio di Target Poisoning
Immaginiamo un sistema di riconoscimento facciale utilizzato per il controllo degli accessi in un’azienda. L’IA è stata addestrata su un dataset di volti autorizzati e non autorizzati.
Fase 1: Iniezione di dati avvelenati
Un attaccante con accesso al dataset di addestramento introduce immagini modificate di sé stesso, in cui appare simile a un dipendente autorizzato. Questo può essere fatto in diversi modi:
- Adversarial Perturbation: piccole modifiche impercettibili ai pixel che ingannano il modello.
- Data Poisoning diretto: caricando nel dataset immagini false di sé stesso etichettate come “autorizzato”.
Fase 2: Effetti dell’attacco
Dopo l’addestramento, il sistema apprende che l’attaccante è un dipendente autorizzato. Ora può accedere liberamente, mentre il sistema continua a funzionare normalmente per tutti gli altri utenti.
Perché è pericoloso
- È un attacco difficile da rilevare: il comportamento dell’IA è normale nella maggior parte dei casi.
- L’attacco è mirato a una specifica condizione.
- Se l’attaccante usa tecniche avanzate come clean-label poisoning (senza dati evidentemente errati), l’attacco è quasi invisibile.
Questa tecnica può essere applicata in molti ambiti, come il filtraggio di spam, i sistemi di raccomandazione e i modelli di previsione delle frodi.
Esempio di Backdoor Poisoning
Immaginiamo un sistema di riconoscimento dei segnali stradali basato su IA, utilizzato nei veicoli a guida autonoma per identificare segnali di stop e limiti di velocità.
Fase 1: Manipolazione dei dati di addestramento
Un attaccante introduce nel dataset immagini “avvelenate”, come:
- Foto di segnali di STOP con un piccolo adesivo giallo (il trigger).
- Queste immagini vengono etichettate erroneamente come “Limite di velocità 100 km/h” invece che come “STOP”.
Poiché il numero di immagini modificate è piccolo rispetto all’intero dataset, il modello continua a funzionare correttamente nella maggior parte dei casi.
Fase 2: Attivazione della backdoor
Dopo l’addestramento, il modello riconosce normalmente i segnali di STOP, tranne quando c’è il trigger (l’adesivo giallo). Se un malintenzionato applica questo adesivo su un vero segnale di STOP, l’auto non si fermerà, credendo di vedere un cartello di “100 km/h”.
Perché è pericoloso?
- Difficile da rilevare: il modello sembra comportarsi normalmente nei test standard.
- Attivazione selettiva: la backdoor si attiva solo con il trigger specifico.
- Applicabilità ampia: può essere usata in sistemi di autenticazione biometrica, filtraggio di contenuti, riconoscimento vocale, ecc.
Questa tecnica è stata dimostrata in vari studi accademici, come l’attacco BadNets1, e può avere implicazioni serie per la sicurezza dell’IA.
Esempio pratico di Membership Inference Attack
Immaginiamo una clinica che ha addestrato un modello di IA per prevedere la probabilità di sviluppare una malattia rara in base a dati medici dei pazienti.
Fase 1: Il modello predittivo
La clinica utilizza i dati sanitari di migliaia di pazienti per addestrare un modello di machine learning. Questo modello è poi reso disponibile online come API pubblica, dove gli utenti possono inserire i propri dati e ottenere una previsione sul rischio della malattia.
Fase 2: L’attacco di inference
Un attaccante vuole scoprire se una persona specifica (ad esempio, un politico famoso) era inclusa nel dataset di addestramento. Per farlo:
- Ottiene alcuni dati medici pubblici o approssimati della vittima.
- Esegue query al modello online con dati simili, osservando la risposta.
- Confronta la fiducia delle predizioni: i modelli tendono ad avere maggiore confidenza nei dati visti durante l’addestramento rispetto a quelli nuovi.
Se il modello restituisce una previsione con un’alta sicurezza per i dati della vittima, è probabile che questi fossero nel dataset di training.
Perché è pericoloso?
- Privacy violata: se il dataset conteneva informazioni sensibili (es. cartelle cliniche), un attaccante può scoprire chi ne faceva parte.
- Applicabilità ampia: attacchi simili possono essere eseguiti su modelli di riconoscimento facciale, raccomandazioni, analisi del credito, ecc.
- Non richiede accesso ai dati interni: può essere eseguito solo interrogando un’API pubblica.
Questa vulnerabilità è stata studiata in vari contesti, e mitigazioni come la Differential Privacy2 possono ridurre il rischio: nel 2020, gli Stati Uniti hanno usato la DP per anonimizzare i dati oggetto di censimento demografico.
Conclusioni
L’aumento della complessità di elaborazione delle informazioni ha generato nuove modalità di attacco e nuovi scenari offensivi. In tal senso è ovvio e necessario che le organizzazioni si proteggano ma, se si sbagliasse la metodologia, la linea di difesa rischierebbe di diventare troppo rigida e bloccante. È necessario adottare uno o più modelli metodologici che siano da una parte aderenti agli standard, dall’altra parte realmente sostenibili per le organizzazioni. Il tutto, chiaramente, è ulteriormente reso più complesso dall’introduzione dell’intelligenza artificiale che richiede controlli specifici e una collaborazione molto stretta con i fornitori.
Note
- Un attacco BadNets è una forma di backdoor attack applicata ai modelli di machine learning (ML), in particolare alle reti neurali profonde (DNN, Deep Neural Networks). Questo tipo di attacco viene realizzato introducendo intenzionalmente una backdoor (una sorta di “cavallo di Troia”) durante la fase di addestramento del modello, con l’obiettivo di farlo funzionare normalmente nella maggior parte dei casi, ma rispondere in modo malevolo quando incontra un trigger specifico. La mitigazione di questa tipologia di attacco è complessa e si basa, prevalentemente, sulla verifica delle sorgenti dati. ↩︎
- Differential Privacy (DP) è una tecnica utilizzata per proteggere la privacy dei dati personali nei dataset analizzati da algoritmi di machine learning, statistiche o altri processi computazionali. L’obiettivo principale è garantire che i risultati dell’analisi non rivelino informazioni specifiche su alcun individuo, anche se un attaccante avesse accesso a tutto il resto del dataset. I vantaggi sono: la protezione delle informazioni anche con accesso ai dati e il fatto che non si possa combinare con altre tecniche di machine learning per un’analisi più sicura. Gli svantaggi sono una riduzione della precisione di analisi, una difficoltà di implementazione in taluni contesti reali e comunque obbliga ad un compromesso tra privacy ed utilità dei dati. ↩︎
