
C’è ancora molta confusione in merito al concetto di pseudonimizzazione, ossia a quel procedimento con il quale s’impedisce di identificare un individuo attraverso i suoi dati. Il GDPR è particolarmente rigido in termini di pseudonimizzazione: l’impossibilità di risalire all’identità del proprietario dei dati deve essere assoluta.
Principi generali
Iniziamo dalle basi, l’articolo 4 (Definizioni) comma 5, restituisce il concetto di pseudonimizzazione:
“Il trattamento dei dati personali in modo tale che i dati personali non possano più essere attribuiti a un interessato specifico senza l’utilizzo di informazioni aggiuntive, a condizione che tali informazioni aggiuntive siano conservate separatamente e soggette a misure tecniche e organizzative intese a garantire che tali dati personali non siano attribuiti a una persona fisica identificata o identificabile”
GDPR – Art. 4 comma 5
C’è però di più: pensare che la pseudonimizzazione si possa raggiungere con l’ausilio di un software è rischioso. L’anonimato è garantito da due fronti operativi diversi ma correlati: quello organizzativo e quello tecnologico. Il primo si prepara a gestire il valore del dato disaccoppiandolo definitivamente dall’identità individuale mentre il secondo supporta tale processo operando le operazioni del caso; la dualità di questi due ambiti è altresì prevista dallo stesso Regolamento al considerando 29:
“Al fine di creare incentivi per l’applicazione della pseudonimizzazione nel trattamento dei dati personali, dovrebbero essere possibili misure di pseudonimizzazione con possibilità di analisi generale all’interno dello stesso titolare del trattamento, qualora il titolare del trattamento abbia adottato le misure tecniche e organizzative necessarie ad assicurare, per il trattamento interessato, l’attuazione del presente regolamento, e che le informazioni aggiuntive per l’attribuzione dei dati personali a un interessato specifico siano conservate separatamente.”
GDPR – Considerando 29
Ma cosa c’è alla base della pseudonimizzazione? Ovviamente l’individuo e la sua identità ed il GDPR comincia a parlare di questa misura fin dal considerando 26 con il quale prova a fornire una spiegazione circa l’applicazione di tale misura:
“L’applicazione della pseudonimizzazione ai dati personali può ridurre i rischi per gli interessati e aiutare i titolari del trattamento e i responsabili del trattamento a rispettare i loro obblighi di protezione dei dati. L’introduzione esplicita della «pseudonimizzazione» nel presente regolamento non è quindi intesa a precludere altre misure di protezione dei dati.”
GDPR – Considerando 26
Se ne deduce un aspetto molto importante: l’applicazione di cui non è esclusiva, anzi va integrata al compendio delle altre misure al fine di garantire un livello di sicurezza maggiore dei dati personali dell’utente finale. In ambito sanitario, così come in quello finanziario, questa misura assume una rilevanza particolare sia per l’utente finale che per l’azienda che può continuare ad usufruire del valore dei dati seppur pseudonimizzati.
L’anonimizzazione
Un altro errore molto comune è la confusione tra pseudonimizzazione e anonimizzazione: si tratta di una differenza molto sottile ma profondamente importante. Non esiste nelle “Definizioni” una voce specifica per il concetto di dato anonimo o informazione anonima, la si può efficacemente ricavare dal Considerando 26:
“I principi di protezione dei dati non dovrebbero pertanto applicarsi a informazioni anonime, vale a dire informazioni che non si riferiscono a una persona fisica identificata o identificabile o a dati personali resi sufficientemente anonimi da impedire o da non consentire più l’identificazione dell’interessato.”
GDPR – Considerando 26
Quindi la differenza essenziale è che, mentre un dato pseudonimizzato può correre il rischio di essere ricostruito, un dato anonimo non è “ricostruibile” e non è pertanto possibile re-identificare l’identità dell’utente. Ecco perché nel Considerando 75 si parla del rischio di “decifratura non autorizzata della pseudonimizzazione”; e generalmente questa procedura si attua attraverso un principio di “disaccoppiamento” tra le informazioni personali di identificazione e le altre.
“dati personali che rivelano l’origine razziale o etnica, le opinioni politiche, le convinzioni religiose o filosofiche, l’appartenenza sindacale, nonché dati genetici, dati relativi alla salute o i dati relativi alla vita sessuale o a condanne penali e a reati o alle relative misure di sicurezza; in caso di valutazione di aspetti personali, in particolare mediante l’analisi o la previsione di aspetti riguardanti il rendimento professionale, la situazione economica, la salute, le preferenze o gli interessi personali, l’affidabilità o il comportamento, l’ubicazione o gli spostamenti, al fine di creare o utilizzare profili personali; se sono trattati dati personali di persone fisiche vulnerabili, in particolare minori; se il trattamento riguarda una notevole quantità di dati personali e un vasto numero di interessati.”
GDPR – Considerando 75
La pseudonimizzazione viene resa possibile da numerose tecnologie che, sulla base dei privilegi utente, hanno la possibilità di mantenere visibili solo una parte delle informazioni totali tenendo oscurate le altre. Se immaginassimo, ad esempio, una schermata applicativa vista a scopo sanitario, potremmo paragonarla a qualcosa di simile:
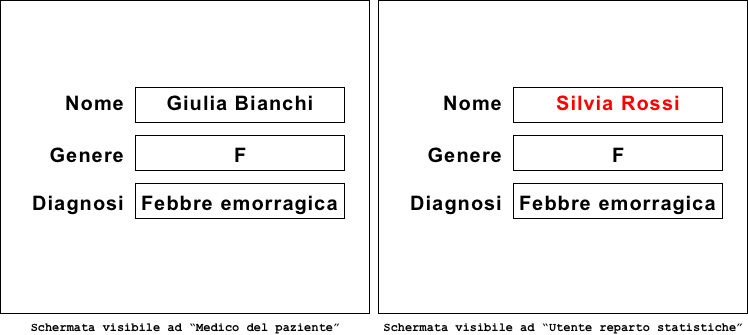
Come è possibile notare la vista del “Medico del paziente” è completa perché, per ragioni lavorative, egli ha bisogno di tutti i dati necessari allo svolgimento della pratica medica e del trattamento del suo paziente. Gli stessi dati, visti da un “Utente del reparto statistiche”, apparirebbero pseudonimizzati ed il nome “Silvia Rossi” in sostituzione dell’originale può essere preso casualmente da una bancadati preposta o da un’altra lista dati. La pseudonimizzazione è quindi utile perché permette di proteggere il dato durante la sua vita, offrendo un grado di privacy dal valore inestimabile.
La pseudonimizzazione può esser quindi garantita da un sistema che, sulla base del ruolo utente, stabilisce quali informazioni mostrare quali celare e ciò che viene celato può esser oggetto di cifratura in modo che forzando il sistema non si riesca a risolvere l’informazione. Il punto debole del sistema di pseudonimizzazione è nella logica applicativa che “scambia i dati” da presentare all’utente: il codice applicativo dovrà quindi essere solido, ben scritto e dovranno essere applicate severe misure di sicurezza sulle banche dati per mettere in sicurezza il contenuto dei singoli campi.
Altra cosa invece è l’anonimizzazione che rende impossibile ricostruire l’informazione per chiunque. Se applicato durante la vita operativa del dato in relazione all’esempio sopra penalizzerebbe il “Medico del paziente” che non riuscirebbe più a riconoscere i dati di Giulia Bianchi. L’anonimizzazione si può utilizzare al termine del periodo d’uso contrattuale dei dati personali e allora il nome di Giulia Bianchi potrebbe essere semplicemente sostituito con qualcosa che ne impedisca il riconoscimento nel tempo.
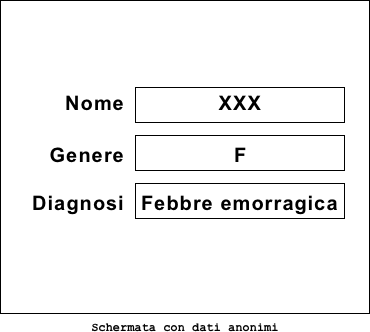
A questo punto diviene impossibile per chiunque, anche per il “Medico del paziente”, associare “XXX” all’utente “Giulia Bianchi”, non si tratta quindi di una cifratura o di un’alterazione temporanea e reversibile del dato ma di una vera e propria cancellazione con sostituzione di una stringa senza valore ed in alcun modo legata all’identificazione dell’utente originario.
Una via di mezzo tra la pseudonimizzazione e l’anonimizzazione è l’oscuramento di specifiche informazioni, impedendo l’accesso tramite logiche legate all’applicazione e al database che contiene i dati. Non viene quindi usato uno pseudonimo ma viene rispettata comunque la privacy dell’utente finale. Se volessimo provare ad effettuare un confronto tra le situazioni sopra esposte potremmo immaginarle come segue.

A sinistra i dati “in chiaro” possono apparire al medico che ha in cura Giulia Bianchi. L’utilizzo di uno pseudonimo può essere utilizzato per proteggere l’identità della Sig. Bianchi cambiandole nome e facendo in modo che altri operatori autorizzati a trattare specifici (ad esempio quelli sulle malattie) non abbiano a leggere il nome autentico della persona. Alternativamente allo pseudonimo può essere vietato l’accesso al singolo dato tramite meccanismi di protezione dei database applicativi. Una volta cessato lo scopo di utilizzo dei dati, la scheda viene resa anonima sostituendo il nome ad una stringa senza valore, con irreversibilità rispetto ai due metodi precedenti.
Conclusioni
In conclusione, il processo di pseudonimizzazione o di oscuramento parziale del dato è affidato a logiche tecniche e organizzative che devono essere solide e ben strutturate. La logica applicativa che permette al software di pseudonimizzare i dati deve essere impeccabile e garantire sicurezza durante il ciclo di vita e operatività delle informazioni. La pseudonimizzazione o l’oscuramento parziale dei dati sono processi reversibili che hanno logiche applicative, costi e rischi differenti. L’anonimizzazione, prevista al termine del periodo contrattuale dell’uso dei dati personali, è irreversibile e consiste nella sostituzione permanente del dato personale con una stringa senza alcun valore e a carattere assolutamente generico.
Il corretto impiego di queste tecniche è fondamentale per il mantenimento della privacy dell’utente anche in campi dove, apparentemente, le informazioni possono apparire meno esposte a rischi ed è quindi rilevante la loro corretta applicazione.
Riferimenti bilbiografici
- Regolamento EU 679/2016 (GDPR): https://eur-lex.europa.eu/legal-content/IT/TXT/HTML/?uri=CELEX:32016R0679&from=IT
